
2018机器阅读理解技术竞赛“发榜” 百度开放数据集成就“头号玩家”
近日,由中国中文信息学会(CIPS)、中国计算机学会(CCF)和百度公司联手举办的“2018机器阅读理解技术竞赛”落下帷幕。来自北京奇点机智科技有限公司的韦琬和刘家骅组成的Naturali团队凭借在自然语言处理(NLP)领域多年的积累与沉淀,从国内外1000多支报名队伍中脱颖而出荣获第一名。大赛更多排名信息,可登录2018机器阅读理解技术竞赛官网http://mrc2018.cipsc.org.cn/查看。

本次竞赛旨在推动语言理解和人工智能领域技术和应用的发展,通过机器阅读文本,进而回答和阅读内容相关的问题。比赛涉及到了语言理解、知识推理、摘要生成等复杂技术,极具挑战。大赛有效推动了机器阅读理解技术的发展,更为下一届机器阅读理解技术竞赛的举办积累了宝贵经验。竞赛将在第三届“语言与智能高峰论坛”举办技术交流和颁奖,数据集论文可登录https://arxiv.org/abs/1711.05073查看,供业界交流使用。

用行动见初心,百度提供迄今规模最大的中文阅读理解数据集
本次大赛受到了全球机器阅读理解领域研究者的广泛关注,具有覆盖面广,参与度高,活跃度强的特点。竞赛注册报名团队共达1062支,累计收到系统结果1489份。竞赛基于测试集的人工标注答案,采用ROUGH-L和BLEU4作为评价指标,以ROUGH-L为主评价指标。比赛期间排行榜高分不断刷新,ROUGE-L评价指标由最初的35.96提升至终赛的63.38,接近半数的系统结果超过了基线系统。在各团队的不懈努力下,参赛系统整体水平得到了显著提升。
为了给予参赛者最大力度支持,本次竞赛数据集来自搜索引擎真实应用场景,其中的问题为百度搜索用户的真实问题,每个问题对应5个候选文档文本及人工整理的优质答案,这是目前为止最大、最具挑战性的中文阅读理解数据集。
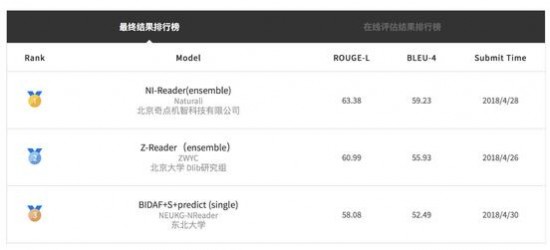
众所周知,近几年来人工智能技术的迅速发展,离不开大量可供机器学习的数据的发布。此次百度公开阅读理解数据集为学术界提供了迄今为止最大规模的真实应用场景下的数据,也带来了相对深层次的答案细节标注。数据中涵盖的丰富信息,可覆盖大量阅读理解及问答的研究需求,并为其他的研究方向提供了大量可发掘利用的信息。毫无疑问,此次百度公开数据集对于推动机器阅读理解技术乃至人工智能技术的发展都有着积极且重要的作用。
助力人才培养,百度用“中国速度”输送精英人才
依托在人工智能领域的发展,百度通过本次“2018机器阅读理解技术竞赛”为学术界和工业界提供了一个公开的阅读理解技术交流平台,协同多方力量共同打磨机器阅读理解这一项人工智能的关键技术,共同发展共同进步,推动学术界和工业界最新研究成果转化为实际生产力。
百度此次与学界、业界共同举办中文阅读理解技术竞赛,对人才发掘与培养的决心显而易见。通过开展诸如机器阅读理解技术竞赛、百度之星开发者大赛、PaddlePaddle AI大赛等众多人工智能行业竞赛,开放海量优质AI数据资源与行业资源赋能AI行业的优质人才,为研究者提供强大的学习驱动力与创造力。正如本次评测委员会成员刘凯所言,“本次竞赛期望进一步普及机器阅读理解技术、降低技术门槛,吸引并培养更多的技术人才,推动我国人工智能的学术和产业的发展。”
本次竞赛结束后,对AI数据集有兴趣的技术人才可以在百度BROAD平台自由下载已公开的阅读理解数据集,并通过平台提交测试集结果进行系统效果测试,持续了解和关注百度阅读理解数据集。除了阅读理解数据集,百度AI公开数据集计划BROAD(Baidu Research Open-Access Dataset)还发布了视频和图像数据集。
我们有理由相信,未来,百度将继续在AI人才培养中发挥重要作用,联合产学研各方开展研究,培养人工智能领域的精英技术人才。

- 2018-05-282018机器阅读理解技术竞赛“
- 2018-05-28天津伊美尔整形医院优质服
- 2018-05-28陈榕:梦想之于他,是十八
- 2018-05-28知乎合伙人李大海亮相腾讯
- 2018-05-25中华小戏骨系列剧之《弟子
- 2018-05-25天津哪家整形医院正规 看天
- 2018-05-25“智慧港口”千人大会即将






